http://gamesfromwithin.com/managing-data-relationships
Managing Data Relationships
I’ve been meaning to put up the rest of the Inner Product columns I wrote for Game Developer Magazine, but I wasn’t finding the time. With all the recent discussion on data-oriented design, I figured it was time to dust some of them off.
This was one of the first columns I wrote. At first glance it might seem a completely introductory topic, not worth spending that much time on it. After all, all experience programmers know about pointers and indices, right? True, but I don’t think all programmers really take the time to think about the advantages and disadvantages of each approach, and how it affects architecture decisions, data organization, and memory traversal.
It should provide a good background for this coming Thursday’s #iDevBlogADay post on how to deal with heterogeneous objects in a data-oriented way.
From a 10,000-Foot view, all video games are just a sequence of bytes. Those bytes can be divided into code and data. Code is executed by the hardware and it performs operations on the data. This code is generated by the compiler and linker from the source code in our favorite computer language. Data is just about everything else. [1]
As programmers, we’re obsessed with code: beautiful algorithms, clean logic, and efficient execution. We spend most of our time thinking about it and make most decisions based on a code-centric view of the game.
Modern hardware architectures have turned things around. A data-centric approach can make much better use of hardware resources, and can produce code that is much simpler to implement, easier to test, and easier to understand. In the next few months, we’ll be looking at different aspects of game data and how everything affects the game. This month we start by looking at how to manage data relationships.
How are those relationships between different parts of data described? There are many approaches we can use, each with its own set of advantages and drawbacks. There isn’t a one-size-fits-all solution. What’s important is choosing the right tool for the job.
However, they have their share of shortcomings. The biggest drawback is that a pointer is just the memory address where the data happens to be located. We often have no control over that location, so pointer values usually change from run to run. This means if we attempt to save a game checkpoint which contains a pointer to other parts of the data, the pointer value will be incorrect when we restore it.
Pointers represent a many-to-one relationship. You can only follow a pointer one way, and it is possible to have many pointers pointing to the same piece of data (for example, many models pointing to the same texture). All of this means that it is not easy to relocate a piece of data that is referred to by pointers. Unless we do some extra bookkeeping, we have no way of knowing what pointers are pointing to the data we want to relocate. And if we move or delete that data, all those pointers won’t just be invalid, they’ll be dangling pointers. They will point to a place in memory that contains something else, but the program will still think it has the original data in it, causing horrible bugs that are no fun to debug.
One last drawback of pointers is that even though they’re easy to use, somewhere, somehow, they need to be set. Because the actual memory location addresses change from run to run, they can’t be computed offline as part of the data build. So we need to have some extra step in the runtime to set the pointers after loading the data so the code can use them. This is usually done either by explicit creation and linking of objects at runtime, by using other methods of identifying data, such as resource UIDs created from hashes, or through pointer fixup tables converting data offsets into real memory addresses. All of it adds some work and complexity to using pointers.
Given those characteristics, pointers are a good fit to model relationships to data that is never deleted or relocated, from data that does not need to be serialized. For example, a character loaded from disk can safely contain pointers to its meshes, skeletons, and animations if we know we’re never going to be moving them around.
The more common approach is to use indices into an array of data. Indices, in addition to being safe to save and restore, have the same advantage as pointers in that they’re very fast, with no extra indirections or possible cache misses.
Unfortunately, they still suffer from the same problem as pointers of being strictly a many-to-one relationship and making it difficult to relocate or delete the data pointed to by the index. Additionally, arrays can only be used to store data of the same type (or different types but of the same size with some extra trickery on our part), which might be too restrictive for some uses.
A good use of indices into an array are particle system descriptions. The game can create instances of particle systems by referring to their description by index into that array. On the other hand, the particle system instances themselves would not be a good candidate to refer to with indices because their lifetimes vary considerably and they will be constantly created and destroyed.
It’s tempting to try and extend this approach to holding pointers in the array instead of the actual data values. That way, we would be able to deal with different types of data. Unfortunately, storing pointers means that we have to go through an extra indirection to reach our data, which incurs a small performance hit. Although this performance hit is something that we’re going to have to live with for any system that allows us to relocate data, the important thing is to keep the performance hit as small as possible.
An even bigger problem is that, if the data is truly heterogeneous, we still need to cast it to the correct type before we use it. Unless all data referred to by the pointers inherits from a common base class that we can use to query for its derived type, we have no easy way to find out what type the data really is.
On the positive side, now that we’ve added an indirection (index to pointer, pointer to data), we could relocate the data, update the pointer in the array, and all the indices would still be valid. We could even delete the data and null the pointer out to indicate it is gone. Unfortunately, what we can’t do is reuse a slot in the array since we don’t know if there’s any data out there using that particular index still referring to the old data.
Because of these drawbacks, indices into an array of pointers is usually not an effective way to keep references to data. It’s usually better to stick with indices into an array of data, or extend the idea a bit further into a handle system, which is much safer and more versatile.
The handle is used as a key into a handle manager, which associates handles with their data. The simplest possible implementation of a handle manager is a list of handle-pointer pairs and every lookup simply traverses the list looking for the handle. This would work but it’s clearly very inefficient. Even sorting the handles and doing a binary search is slow and we can do much better than that.
Here’s an efficient implementation of a handle manager (released under the usual MIT license, so go to town with it). The handle manager is implemented as an array of pointers, and handles are indices into that array. However, to get around the drawbacks of plain indices, handles are enhanced in a couple of ways.
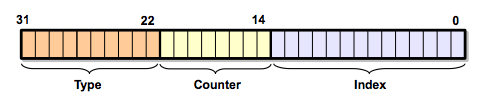
In order to make handles more useful than pointers, we’re going to use up different bits for different purposes. We have a full 32 bits to play with, so this is how we’re going to carve them out:
We can also easily relocate or invalidate existing handles just by updating the entry in the handle manager to point to a new location or to flag it as removed.
Handles are the perfect reference to data that can change locations or even be removed, from data that needs to be serialized. Game entities are usually very dynamic, and are created and destroyed frequently (such as enemies spawning and being destroyed, or projectiles). So any references to game entities would be a good fit for handles, especially if this reference is held from another game entity and its state needs to be saved and restored. Examples of these types of relationships are the object a player is currently holding, or the target an enemy AI has locked onto.
A common type of smart pointer deals with object lifetime. Smart pointers keep track of how many references there are to a particular piece of data, and free it when nobody is using it. For the runtime of games, I prefer to have very explicit object lifetime management, so I’m not a big fan of this kind of pointers. They can be of great help in development for tools written in C++ though.
Another kind of smart pointers insert an indirection between the data holding the pointer and the data being pointed. This allows data to be relocated, like we could do with handles. However, implementations of these pointers are often non- serializable, so they can be quite limiting.
If you consider using smart pointers from some of the popular libraries (STL, Boost) in your game, you should be very careful about the impact they can have on your build times. Including a single header file from one of those libraries will often pull in numerous other header files. Additionally, smart pointers are often templated, so the compiler will do some extra work generating code for each data type you instantiated templates on. All in all, templated smart pointers can have a significant impact in build times unless they are managed very carefully.
It’s possible to implement a smart pointer that wraps handles, provides a syntax like a regular pointer, and it still consists of a handle underneath, which can be serialized without any problem. But is the extra complexity of that layer worth the syntax benefits it provides? It will depend on your team and what you’re used to, but it’s always an option if the team is more comfortable dealing with pointers instead of handles.
In the next few months, we’ll continue talking about data, and maybe even convince you that putting some love into your data can pay off big time with your code and the game as a whole.
This article was originally printed in the September 2008 issue of Game Developer.
[1] I'm not too happy about the strong distinction I was making between code and data. Really, data is any byte in memory, and that includes code. Most of the time programs are going to be managing references to non-code data, but sometimes to other code as well: function pointers, compiled shaders, compiled scripts, etc. So just ignore that distinction and think of data in a more generic way.
This was one of the first columns I wrote. At first glance it might seem a completely introductory topic, not worth spending that much time on it. After all, all experience programmers know about pointers and indices, right? True, but I don’t think all programmers really take the time to think about the advantages and disadvantages of each approach, and how it affects architecture decisions, data organization, and memory traversal.
It should provide a good background for this coming Thursday’s #iDevBlogADay post on how to deal with heterogeneous objects in a data-oriented way.
From a 10,000-Foot view, all video games are just a sequence of bytes. Those bytes can be divided into code and data. Code is executed by the hardware and it performs operations on the data. This code is generated by the compiler and linker from the source code in our favorite computer language. Data is just about everything else. [1]
As programmers, we’re obsessed with code: beautiful algorithms, clean logic, and efficient execution. We spend most of our time thinking about it and make most decisions based on a code-centric view of the game.
Modern hardware architectures have turned things around. A data-centric approach can make much better use of hardware resources, and can produce code that is much simpler to implement, easier to test, and easier to understand. In the next few months, we’ll be looking at different aspects of game data and how everything affects the game. This month we start by looking at how to manage data relationships.
Data Relationships
Data is everything that is not code: meshes and textures, animations and skeletons, game entities and pathfinding networks, sounds and text, cut scene descriptions and dialog trees. Our lives would be made simpler if data simply lived in memory, each bit totally isolated from the rest, but that’s not the case. In a game, just about all the data is intertwined in some way. A model refers to the meshes it contains, a character needs to know about its skeleton and its animations, and a special effect points to textures and sounds.How are those relationships between different parts of data described? There are many approaches we can use, each with its own set of advantages and drawbacks. There isn’t a one-size-fits-all solution. What’s important is choosing the right tool for the job.
Pointing The Way
In C++, regular pointers (as opposed to “smart pointers” which we’ll discuss later on) are the easiest and most straightforward way to refer to other data. Following a pointer is a very fast operation, and pointers are strongly typed, so it’s always clear what type of data they’re pointing to.However, they have their share of shortcomings. The biggest drawback is that a pointer is just the memory address where the data happens to be located. We often have no control over that location, so pointer values usually change from run to run. This means if we attempt to save a game checkpoint which contains a pointer to other parts of the data, the pointer value will be incorrect when we restore it.
Pointers represent a many-to-one relationship. You can only follow a pointer one way, and it is possible to have many pointers pointing to the same piece of data (for example, many models pointing to the same texture). All of this means that it is not easy to relocate a piece of data that is referred to by pointers. Unless we do some extra bookkeeping, we have no way of knowing what pointers are pointing to the data we want to relocate. And if we move or delete that data, all those pointers won’t just be invalid, they’ll be dangling pointers. They will point to a place in memory that contains something else, but the program will still think it has the original data in it, causing horrible bugs that are no fun to debug.
One last drawback of pointers is that even though they’re easy to use, somewhere, somehow, they need to be set. Because the actual memory location addresses change from run to run, they can’t be computed offline as part of the data build. So we need to have some extra step in the runtime to set the pointers after loading the data so the code can use them. This is usually done either by explicit creation and linking of objects at runtime, by using other methods of identifying data, such as resource UIDs created from hashes, or through pointer fixup tables converting data offsets into real memory addresses. All of it adds some work and complexity to using pointers.
Given those characteristics, pointers are a good fit to model relationships to data that is never deleted or relocated, from data that does not need to be serialized. For example, a character loaded from disk can safely contain pointers to its meshes, skeletons, and animations if we know we’re never going to be moving them around.
Indexing
One way to get around the limitation of not being able to save and restore pointer values is to use offsets into a block of data. The problem with plain offsets is that the memory location pointed to by the offset then needs to be cast to the correct data type, which is cumbersome and prone to error.The more common approach is to use indices into an array of data. Indices, in addition to being safe to save and restore, have the same advantage as pointers in that they’re very fast, with no extra indirections or possible cache misses.
Unfortunately, they still suffer from the same problem as pointers of being strictly a many-to-one relationship and making it difficult to relocate or delete the data pointed to by the index. Additionally, arrays can only be used to store data of the same type (or different types but of the same size with some extra trickery on our part), which might be too restrictive for some uses.
A good use of indices into an array are particle system descriptions. The game can create instances of particle systems by referring to their description by index into that array. On the other hand, the particle system instances themselves would not be a good candidate to refer to with indices because their lifetimes vary considerably and they will be constantly created and destroyed.
It’s tempting to try and extend this approach to holding pointers in the array instead of the actual data values. That way, we would be able to deal with different types of data. Unfortunately, storing pointers means that we have to go through an extra indirection to reach our data, which incurs a small performance hit. Although this performance hit is something that we’re going to have to live with for any system that allows us to relocate data, the important thing is to keep the performance hit as small as possible.
An even bigger problem is that, if the data is truly heterogeneous, we still need to cast it to the correct type before we use it. Unless all data referred to by the pointers inherits from a common base class that we can use to query for its derived type, we have no easy way to find out what type the data really is.
On the positive side, now that we’ve added an indirection (index to pointer, pointer to data), we could relocate the data, update the pointer in the array, and all the indices would still be valid. We could even delete the data and null the pointer out to indicate it is gone. Unfortunately, what we can’t do is reuse a slot in the array since we don’t know if there’s any data out there using that particular index still referring to the old data.
Because of these drawbacks, indices into an array of pointers is usually not an effective way to keep references to data. It’s usually better to stick with indices into an array of data, or extend the idea a bit further into a handle system, which is much safer and more versatile.
Handle-Ing The Problem
Handles are small units of data (32 bits typically) that uniquely identify some other part of data. Unlike pointers, however, handles can be safely serialized and remain valid after they’re restored. They also have the advantages of being updatable to refer to data that has been relocated or deleted, and can be implemented with minimal performance overhead.The handle is used as a key into a handle manager, which associates handles with their data. The simplest possible implementation of a handle manager is a list of handle-pointer pairs and every lookup simply traverses the list looking for the handle. This would work but it’s clearly very inefficient. Even sorting the handles and doing a binary search is slow and we can do much better than that.
Here’s an efficient implementation of a handle manager (released under the usual MIT license, so go to town with it). The handle manager is implemented as an array of pointers, and handles are indices into that array. However, to get around the drawbacks of plain indices, handles are enhanced in a couple of ways.
In order to make handles more useful than pointers, we’re going to use up different bits for different purposes. We have a full 32 bits to play with, so this is how we’re going to carve them out:
- The index field. These bits will make up the actual index into the handle manager, so going from a handle to the pointer is a very fast operation. We should make this field as large as we need to, depending on how many handles we plan on having active at once. 14 bits give us over 16,000 handles, which seems plenty for most applications. But if you really need more, you can always use up a couple more bits and get up to 65,000 handles.
- The counter field. This is the key to making this type of handle implementation work. We want to make sure we can delete handles and reuse their indices when we need to. But if some part of the game is holding on to a handle that gets deleted—and eventually that slot gets reused with a new handle—how can we detect that the old handle is invalid? The counter field is the answer. This field contains a number that goes up every time the index slot is reused. Whenever the handle manager tries to convert a handle into a pointer, it first checks that the counter field matches with the stored entry. Otherwise, it knows the handle is expired and returns null.
- The type field. This field indicates what type of data the pointer is pointing to. There are usually not that many different data types in the same handle manager, so 6–8 bits are usually enough. If you’re storing homogeneous data, or all your data inherits from a common base class, then you might not need a type field at all.
struct Handle
{
Handle() : m_index(0), m_counter(0), m_type(0)
{}
Handle(uint32 index, uint32 counter, uint32 type)
: m_index(index), m_counter(counter), m_type(type)
{}
inline operator uint32() const;
uint32 m_index : 12;
uint32 m_counter : 15;
uint32 m_type : 5;
};
Handle::operator uint32() const
{
return m_type << 27 | m_counter << 12 | m_index;
}
The workings of the handle manager itself are pretty simple. It contains an array of HandleEntry types, and each HandleEntry has a pointer to the data and a few other bookkeeping fields: freelist indices for efficient addition to the array, the counter field corresponding to each entry, and some flags indicating whether an entry is in use or it’s the end of the freelist.struct HandleEntry
{
HandleEntry();
explicit HandleEntry(uint32 nextFreeIndex);
uint32 m_nextFreeIndex : 12;
uint32 m_counter : 15;
uint32 m_active : 1;
uint32 m_endOfList : 1;
void* m_entry;
};
Accessing data from a handle is just a matter of getting the index from the handle, verifying that the counters in the handle and the handle manager entry are the same, and accessing the pointer. Just one level of indirection and very fast performance.We can also easily relocate or invalidate existing handles just by updating the entry in the handle manager to point to a new location or to flag it as removed.
Handles are the perfect reference to data that can change locations or even be removed, from data that needs to be serialized. Game entities are usually very dynamic, and are created and destroyed frequently (such as enemies spawning and being destroyed, or projectiles). So any references to game entities would be a good fit for handles, especially if this reference is held from another game entity and its state needs to be saved and restored. Examples of these types of relationships are the object a player is currently holding, or the target an enemy AI has locked onto.
Getting Smarter
The term smart pointers encompasses many different classes that give pointer-like syntax to reference data, but offer some extra features on top of “raw” pointers.A common type of smart pointer deals with object lifetime. Smart pointers keep track of how many references there are to a particular piece of data, and free it when nobody is using it. For the runtime of games, I prefer to have very explicit object lifetime management, so I’m not a big fan of this kind of pointers. They can be of great help in development for tools written in C++ though.
Another kind of smart pointers insert an indirection between the data holding the pointer and the data being pointed. This allows data to be relocated, like we could do with handles. However, implementations of these pointers are often non- serializable, so they can be quite limiting.
If you consider using smart pointers from some of the popular libraries (STL, Boost) in your game, you should be very careful about the impact they can have on your build times. Including a single header file from one of those libraries will often pull in numerous other header files. Additionally, smart pointers are often templated, so the compiler will do some extra work generating code for each data type you instantiated templates on. All in all, templated smart pointers can have a significant impact in build times unless they are managed very carefully.
It’s possible to implement a smart pointer that wraps handles, provides a syntax like a regular pointer, and it still consists of a handle underneath, which can be serialized without any problem. But is the extra complexity of that layer worth the syntax benefits it provides? It will depend on your team and what you’re used to, but it’s always an option if the team is more comfortable dealing with pointers instead of handles.
Conclusion
There are many different approaches to expressing data relationships. It’s important to remember that different data types are better suited to some approaches than others. Pick the right method for your data and make sure it’s clear which one you’re using.In the next few months, we’ll continue talking about data, and maybe even convince you that putting some love into your data can pay off big time with your code and the game as a whole.
This article was originally printed in the September 2008 issue of Game Developer.
[1] I'm not too happy about the strong distinction I was making between code and data. Really, data is any byte in memory, and that includes code. Most of the time programs are going to be managing references to non-code data, but sometimes to other code as well: function pointers, compiled shaders, compiled scripts, etc. So just ignore that distinction and think of data in a more generic way.
没有评论:
发表评论